Instagram ist eine kostenlose App zum Teilen, liken und kommentieren von Fotos und Videos. Mithilfe der App kann man von seinem Smartphone Bilder und Videos aufnehmen, mit Filtern bearbeiten und anschließend im Netzwerk hochladen, um sie mit seinen Freunden zu teilen. Man kann sie mit der ganzen Welt teilen, nur den ausgewählten Follower*innen oder lediglich einigen engen Freund*innen. Jedes Mitglied hat bei Instagram einen Benutzernamen, unter dem es auch dort zu finden ist. Das bedeutet, die Mitglieder verbinden sich miteinander, indem sie anderen folgen, ihre Beiträge ansehen und diese gegebenenfalls „liken“. Außerdem kann man Beiträge anderer kommentieren. Die App entstand 2010, das Unternehmen wuchs schnell und wurde schließlich von Facebook 2012 für ca. eine Milliarde US-Dollar aufgekauft. Die Zahl der Nutzenden liegt mittlerweile bei über 300 Millionen.
Warum besitzt fast jeder ein Instagram-Account und warum verbinde ich mit Instagram sofort Fake-Accounts?
Bei der Suche nach meinem digitalen Objekt ist mir der Gedanke durch den Kopf gegangen, welche Social Media App ich am meisten nutze. Es gibt zahlreiche Apps, die ich auf meinem Handy besitze und verwende, doch keine ist von mir so häufig genutzt wie Instagram.
Ich besitze selbst einen Instagram-Account und kann mir mein Leben kaum mehr ohne die Möglichkeit vorstellen, Instagram zu nutzen. Täglich schaue ich nach neuen Inspirationen für Restaurants, Ausgehmöglichkeiten, Outfits und vielem mehr. Mir fällt oft gar nicht selbst auf, wie viel Zeit ich damit verwende, meine Tweets durchzugehen und zu stöbern. Es macht Spaß mit Freunden Fotos zu teilen, zu kommunizieren und zu surfen. Instagram bietet auf allen Ebenen und jedem die Möglichkeit seine Zeit zu vertreiben und zu surfen!
Jedoch verbinde ich mittlerweile auch mit Instagram Druck auf mich selbst durch die ständig perfekt gestylten Menschen. Es gibt keine offizielle Diagnose, die lauten würde: Social-Media-Abhängigkeit. Doch Bilder, die von mir gepostet werden und mit „Likes“ versehen worden sind, aktivieren ein Belohnungssystem im Gehirn. Das ist sicherlich ein Grund, warum Leute immer wieder auf die Plattformen zurückkehren, um „Likes“ zu bekommen, das fühlt sich gut an. Wir vergleichen uns immer mehr. Bei manchen Personen kann das zu einem negativen Effekt führen.
Ich habe mal in meiner Familie nachgefragt, was früher zu deren Zeit vergleichbare Dinge waren. Die Antwort lautet: Fotoalben.
Über viele Jahre hinweg wurden die schönsten Momente in Fotoalben hineingeklebt und damit Erinnerungen für die Ewigkeit geschaffen. So ist ein Fotoalbum als Erinnerungsstück schwer zu ersetzen. In ein Fotoalbum werden nur die liebevoll gestalteten Bilder geklebt, man findet selten ein Fotoalbum mit Bildern auf denen Traurigkeit, Wut oder Negativität zu sehen sind. Ich sehe hier Parallelen zu Instagram. Die Nutzer*innen achten darauf, dass ihre Bilder mit Filtern und Bearbeitungen gepostet werden, weil alles perfekt erscheinen muss.
Ich erkenne durch den Wandel der Digitalisierung Chancen und Risiken für uns selbst.
Wir entscheiden bewusst, was wir herausstellen möchten. Wie wir uns beschreiben und welche Fotos dieses Selbstbild unterstreicht. Zugleich gibt es bei Instagram auch Fake-Accounts. Ich habe selbst die Erfahrung gemacht, dass mich Fake-Profile anschreiben, meine Bilder liken oder sogar aufdringlich werden. Hinter dem Account verbirgt sich ein Mensch, der vorgibt eine andere reale oder fiktive Person zu sein. Solche Accounts werden meist erstellt, um die wahre Identität zu verschleiern. Man besitzt die Möglichkeit sein Profil privat zu verwalten, sodass nur deine Freunde deine Posts sehen können. Ich stelle mir oft die Frage, wer mit welchen Grund bei meinem öffentlichen Account meine Posts sieht. Und dann denke ich an das Gefühl von Sicherheit, das ein privates Profil verspricht.
Es gibt öffentliche Profile, die haben viele Fans: die von Influencer*innen. Auch Unternehmen haben die Beliebtheit der Influencer*innen bereits erkannt und nutzen diese für ihr Marketing. So ist es nichts Besonderes mehr, wenn ein Influencerin Werbung für ein Shampoo, eine Haarbürste oder für Klamotten macht. Dies scheint für die meisten Unternehmen sehr lukrativ zu sein. Aber was wäre, wenn Bibi und Co im realen Leben gar nicht existieren würden? Was ist, wenn Marken wie Gucci, Louis Vuitton oder bestimmte Kosmetikmarken ihre Werbung mit gefälschten Aufnahmen machen würden? Ist das eigenartig? Oder sogar interessant, unvorstellbar und gar nicht möglich? Egal in welcher Form, mit Fake-Accounts, die es immer geben wird, muss man zurechtkommen und versuchen, sich nicht davon beeinflussen zu lassen.
Ein Grund, warum ich einen Instagram-Account besitze, ist ein gesellschaftlicher Zwang, das Gefühl eventuell nicht mitreden zu können. Als ob eine Art Sucht dahinter steckt, täglich auf Instagram zu sein. Ich spüre allerdings keinen großen Druck, so auszusehen wie manche Frauen auf Instagram. Natürlich beneide ich die eine oder andere um ihren Urlaub, ihre Taschen oder sonstige Gadgets. Dennoch bleibe ich mir treu auf Instagram und versuche, mein persönliches Empfinden vor negativen Auswirkungen zu bewahren.


 Baruch Gottlieb: I will attach a picture for this. Of course, as an academic he had a small working library at his office and a larger library at home in Wynchwood Park Toronto. When he died many books were brought by his son Eric to Prince Edward County outside of Toronto into his library which he called the “Scriptorium” installed in a large barn-like structure. Andrew McLuhan and the McLuhan Institute is mostly based out of the Scriptorium. There is full information on the collection which is now at the Fisher library of the University of Toronto, including a finding aid and some images etc: https://fisher.library.utoronto.ca/mcluhan-library.
Baruch Gottlieb: I will attach a picture for this. Of course, as an academic he had a small working library at his office and a larger library at home in Wynchwood Park Toronto. When he died many books were brought by his son Eric to Prince Edward County outside of Toronto into his library which he called the “Scriptorium” installed in a large barn-like structure. Andrew McLuhan and the McLuhan Institute is mostly based out of the Scriptorium. There is full information on the collection which is now at the Fisher library of the University of Toronto, including a finding aid and some images etc: https://fisher.library.utoronto.ca/mcluhan-library.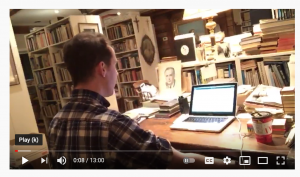 ndrew goes through his father Eric’s library, he does periodic live videos from inside the scriptorium (see attached image) examining what he has found there. The channel also hosts a number of videos featuring Marshall and Eric McLuhan in action.
ndrew goes through his father Eric’s library, he does periodic live videos from inside the scriptorium (see attached image) examining what he has found there. The channel also hosts a number of videos featuring Marshall and Eric McLuhan in action.





















Neueste Kommentare